 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
Reconstructing Images of Two Adjacent Objects through Scattering Medium Using Generative Adversarial Network
Jul 24, 2021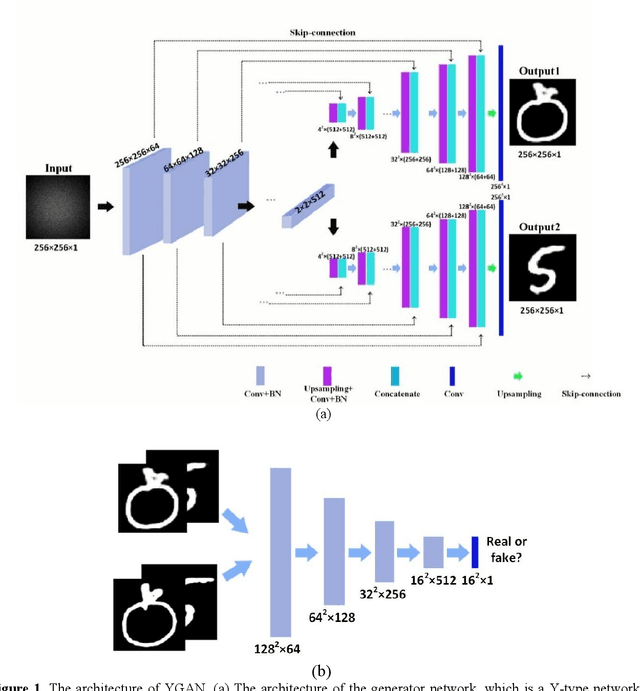
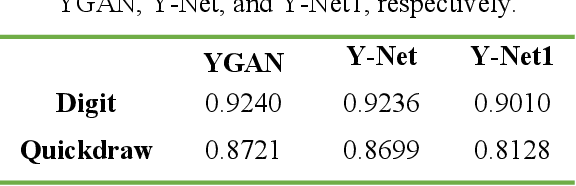
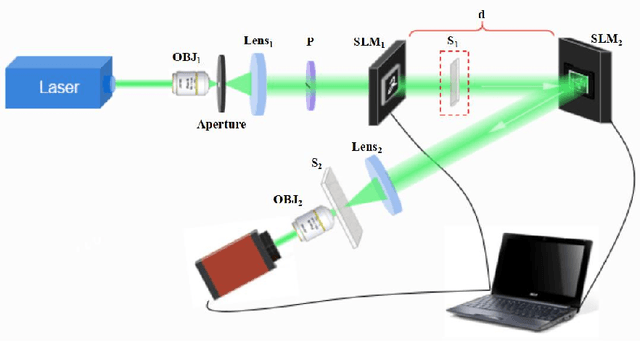
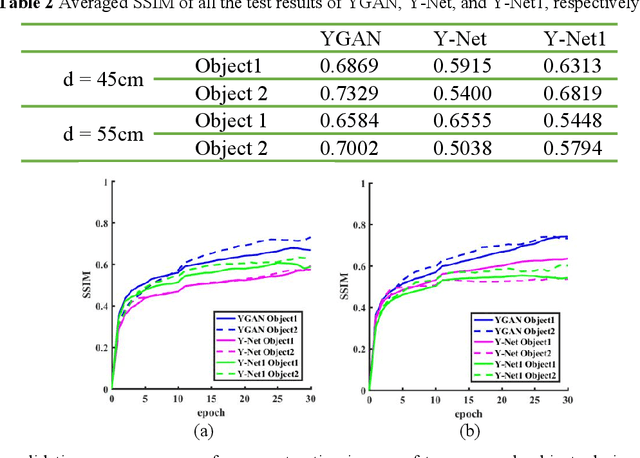
Reconstruction of image by using convolutional neural networks (CNNs) has been vigorously studied in the last decade. Until now, there have being developed several techniques for imaging of a single object through scattering medium by using neural networks, however how to reconstruct images of more than one object simultaneously seems hard to realize. In this paper, we demonstrate an approach by using generative adversarial network (GAN) to reconstruct images of two adjacent objects through scattering media. We construct an imaging system for imaging of two adjacent objects behind the scattering media. In general, as the light field of two adjacent object images pass through the scattering slab, a speckle pattern is obtained. The designed adversarial network, which is called as YGAN, is employed to reconstruct the images simultaneously. It is shown that based on the trained YGAN, we can reconstruct images of two adjacent objects from one speckle pattern with high fidelity. In addition, we study the influence of the object image types, and the distance between the two adjacent objects on the fidelity of the reconstructed images. Moreover even if another scattering medium is inserted between the two objects, we can also reconstruct the images of two objects from a speckle with high quality. The technique presented in this work can be used for applications in areas of medical image analysis, such as medical image classification, segmentation, and studies of multi-object scattering imaging etc.